Machine Learning Lingo and Concepts
Artificial intelligence, machine learning, data science. Those are all different aspects of one field. In this article we’ll focus on machine learning and explain the basic concepts everone should know.
In an earlier article we've discussed why machine learning is powerful. Its potential comes from a combination of being able to deal with complexity, change and scale. Like every field machine learning has its own vocabulary and a few fundamental concepts that are important to understand.
From Inputs to Outputs
We’ll start with an example: An ice cream shop wants to predict how much ice cream they'll sell depending on the temperature outside. First they would collect real data over the course of a few weeks. Then they can take temperature and sales numbers as training examples for an algorithm and train a model. This is the actual "learning" process in machine learning. In the background the algorithm generates a statistical model it can later use to generate sales predictions based on temperature.
In this very basic example we have inputs (temperature) and outputs (sales) which means during training the data metaphorically "supervises" the algorithm to learn the right relation between temperature and sales. This is one of the two big domains of machine learning problems: Supervised learning

Robotic Car ebook
Our step-by-step guide to building a self-driving model car that can navigate your home. Learn all the algorithms and build a real robotic car using a Raspberry Pi.
Sign up now to get exclusive early access and a 50% discount.
Supervised Learning
When our training examples consist of inputs and outputs we can train one of the supervised learning algorithms. In a more complex example if we want to predict daily sales numbers based on day of week, temperature and whether we run an ad campaign on that day, our three inputs would be day-of-week, temperature and ad-campaign. Our output would be sales-in-USD. The inputs are also called features and the outputs are also called target values or labels. Once we’ve decided which input and output values to use we either start to collect these values or take historic data to train the algorithm. When the model performs well enough we can use it in the wild to generate real predictions.
Another example is to predict the probability of a customer churning within a month. Here our inputs may be “has customer contacted support after looking at a help article”, “months since signup”, “affected by outage in last 3 months”, “most recent net promoter score”.
In both examples we try to predict a value. This is called regression.
When we try to predict a category we use classification algorithms. This includes spam detection (we classify the email as spam or not-spam) or object recognition in images.
Unsupervised Learning
For some machine learning tasks we don’t know the expected outputs in advance so we can’t “supervise” the algorithm during training and tell it which outputs we expect from certain inputs. Unsupervised algorithms try to find structure in the input data on their own.
For example if you want to know how to group your customers into customer segments to send them more targeted newsletters you would use a clustering algorithm. You don't know which segment each customer would belong to so you don't have expected outputs for training. But as inputs you could use "frequency of purchases" and "revenue per purchase" and let the clustering algorithm figure out how to best segment those customers.
The difference to classification algorithms is that in clustering you don’t know to which class (or in that case cluster) a customer belongs. The algorithm has to figure this out by itself.
Very often getting large amounts of labeled training data is expensive and so deep learning researchers sometimes pre-train their algorithms on large amounts of unlabeled data they can easily find on the web or in their data centers and then train these prepared models on the actual labeled data.
Generalization
So far we’ve talked about algorithms learning from data as if magically they would just pick up the underlying relationships and learn a perfect model. In practice data has noise and errors. So something as basic as the relation between temperature and revenues might ideally look like this:
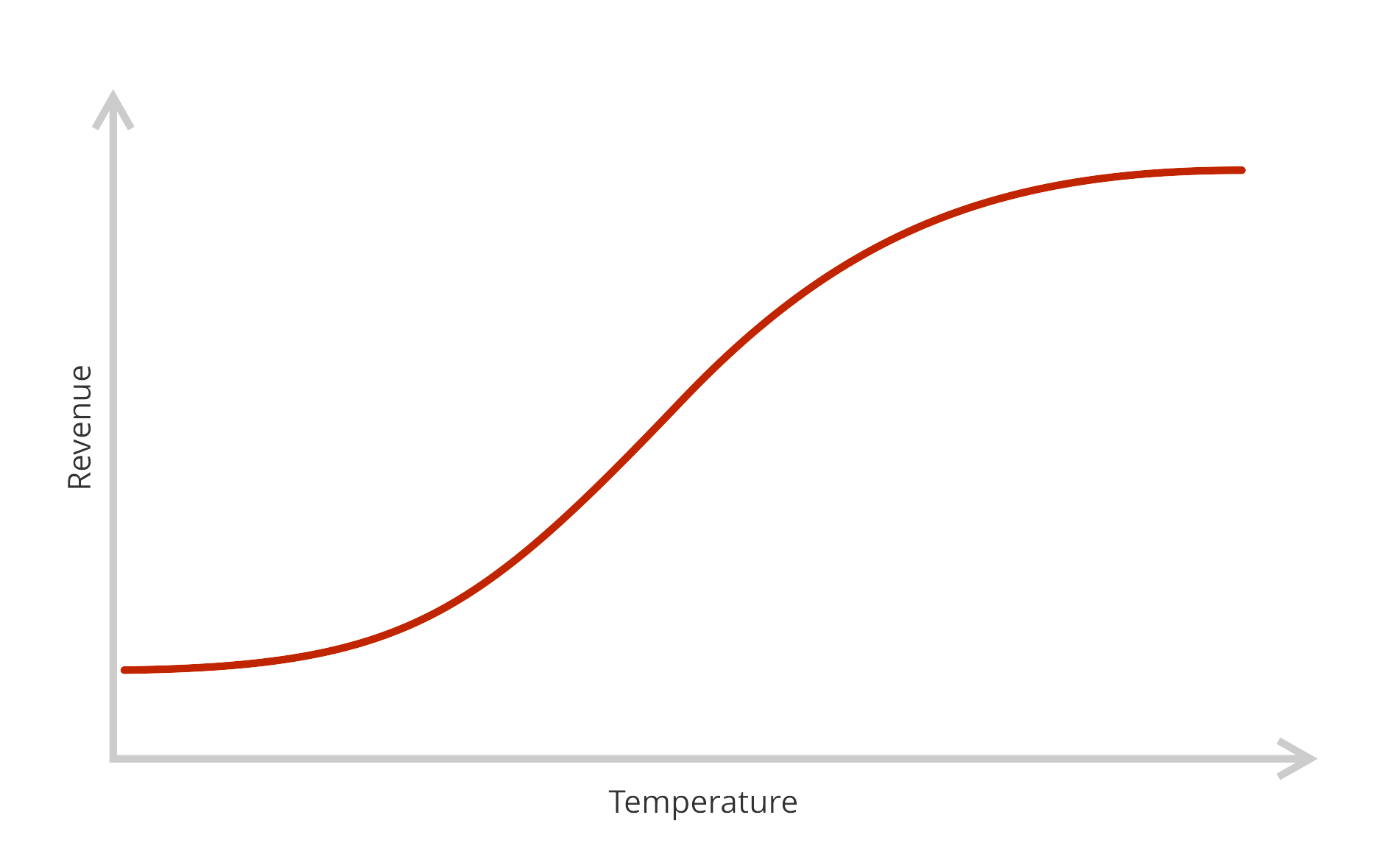
But the data points (daily revenues and daily highest temperature) you collect over a few weeks will look like this:
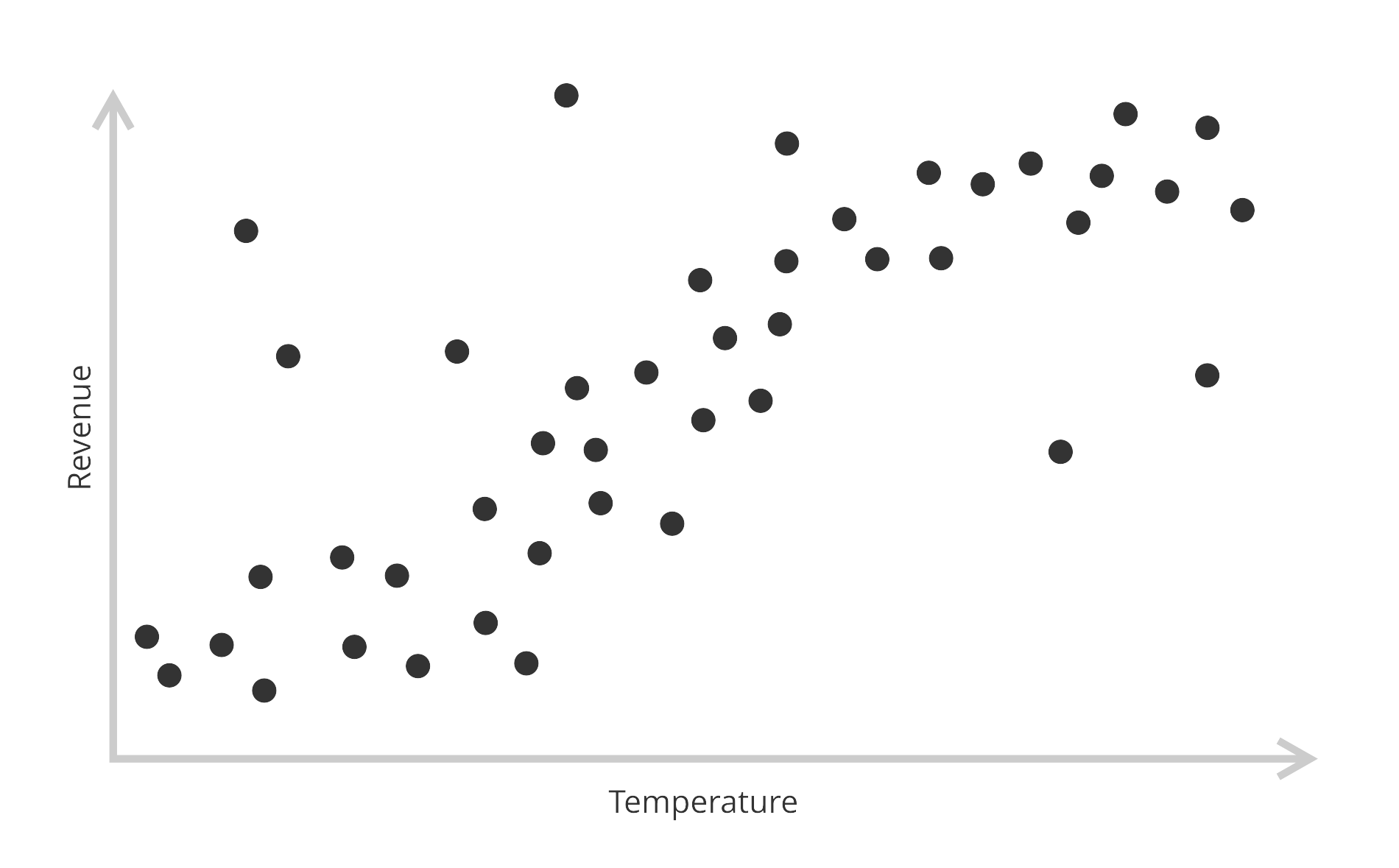
The goal here is to train a model that is simple enough to cut through the noise and only pick up the signal (our perfect curve from the first graph) behind the data points. When the model achieves this it generalizes well.
- When it is too simple it underfits and doesn't catch all nuances of the underlying relation.
- When it is too complex it overfits and just learns all the noise.
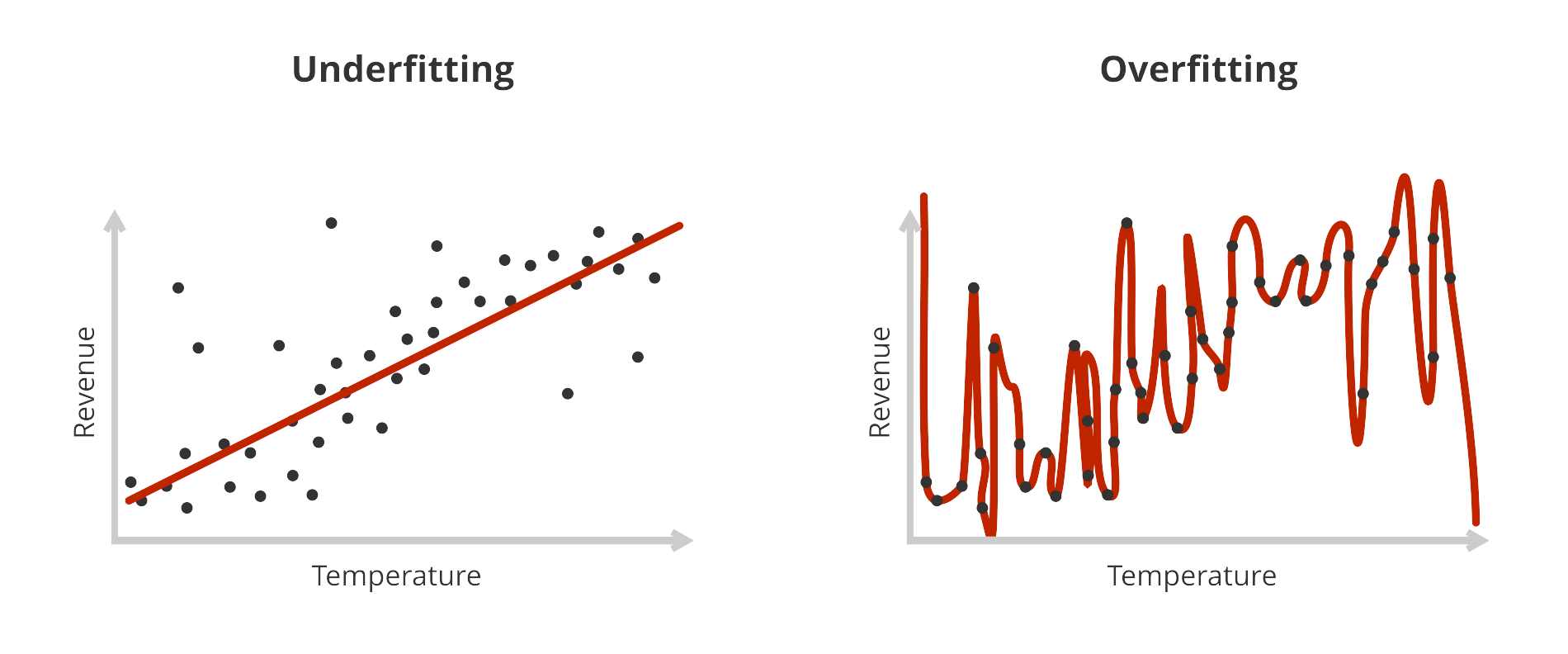
This problem is also called the bias-variance trade-off and is a fundamental concept that follows machine learning researchers, engineers and data scientists their whole lives.
To test how well a learned model generalizes, a model is never trained and tested on the same data. Often the model is trained on a fraction of the available data (typically around 80% to 90%) and then tested with the remaining data it has not seen. More or less simulating how it would fare with new data later on. The resulting score gives a good estimate of how the model will perform with completely new data which ultimately is our main goal.
Summary
We’ve looked at the big concepts in machine learning and this should give you a good overview of what’s possible and where the problems are in machine learning. Here is a very brief summary of the most important notions:
-
Input values/features
The values you feed into an algorithm during training. -
Output values/target values/labels
What you expect the algorithm to return for given input values. -
Supervised learning
Your training dataset has inputs and expected outputs. You train the algorithm to return values similar to these outputs. -
Unsupervised learning
Your training dataset only has inputs. The algorithm will find structure and e.g. return clusters of your datapoints. -
Overfitting (variance)
The model is too complex and just memorizes the noise in your training data. It overfits your data and will not return sensible predictions. -
Underfitting (bias)
The model is too simple and misses important relationships. It underfits your data.
What's next?
You now know about the fundamental machine learning concepts, what to expect and what to watch out for.
Sign up for the newsletter below to be the first to know when we publish the next article.
Email me the next article!
Be the first to get an email when we publish another high-quality article.